
Data science is the most eye-catching field, and data scientists’ job is still the sexiest. As the usefulness of AI and ML proliferates with the new implementation and research verticals, the demand for data scientists is also growing. But the broad universe of data-driven technology takes us to a new horizon of data science job role — the full-stack data scientist’s job role. So, now the question is whether anything of such sort exists? Are full-stack data scientists an actual profile companies are looking forward to or a myth? Again, will it be the new normal for 2022 and the years to come? This article is nothing less than a myth buster and will make the readers witness the future data science profile and what companies are looking forward to in this job profile.
Table of Contents
What does the term “Full-stack” mean?
Full-stack refers to the skills and technologies an individual should possess to complete the entire project. Here each technology or component of the project is called the stack. In other words, they are professionals who have the experience and expertise to develop a project from start to end, leveraging different types of technologies and techniques.
Today, full-stack web developers, full-stack engineers, and full-stack Dev-Ops professionals are some well-known job profiles that companies want to market their products faster. Full-stack data scientist profiles are also becoming a buzzword and gaining popularity. Of course, it is not a myth but will soon become the new normal. It is a next-level data scientist’s job from whom companies are expecting more than usual data scientists’ role. Let’s explore who full-stack data scientists are?
Who are full-stack Data Science?
Approximately 10–12 years ago, when data science came up to a new horizon, large companies like Google, Microsoft, Amazon, etc., hired data scientists. Apart from data scientists responsible for analyzing data and model development, these companies also hired data architecture, BI analysts, data mining professionals, ML engineers, AI-based product developers, analytics teams, etc.
They all help the company support advanced data science operations. Companies hire data scientists because they have a specialization in analyzing and understanding data and can provide the best datasets to train ML models efficiently. But full-stack data scientists have much more responsibility than simply interpreting the best data & modeling the algorithms with efficient datasets.
Although there isn’t any ideal definition of full-stack data scientists, you can explain it descriptively. Full-stack data scientists (FSDS) are those professionals who come with multi-dimensional viewpoints. They are responsible for analyzing large structured and unstructured datasets to extract knowledge and insight from data and implement it in various models and projects. Apart from basic data scientists’ responsibility, they also deploy AI & ML models and integrate different business applications into projects.
They can also develop APIs that leverage complex datasets from cloud storage & understand business needs from applications or APIs for generating better Return on Investment (ROI). A single person can do all the work right from data wrangling & gathering to developing & deploying APIs and ML-driven projects. They cater to multiple expertise such as data analysis, web development, business analytics, sound knowledge of AI & ML, REST API development and deployment, and understanding of its business angle. Apart from all these technical skills, they have a breadth-taking analytical and statistical proficiency. They know which data will bring the best business growth and development.
Skills Needed to Become A Full-Stack Data Scientist
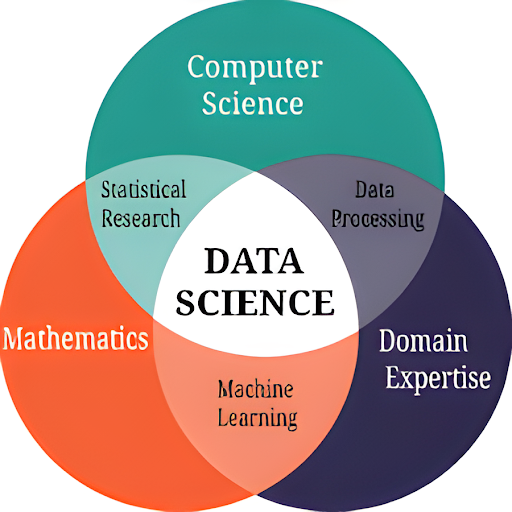
Image Source: Click. in
You’ll need a thorough understanding of various subjects to perform as a full-stack data scientist. You’ll need to have conceptual knowledge and the ability to apply your knowledge in multiple situations. Mathematics, databases/analytics, machine learning, computer science basics, data workflows, model deployments, and industry knowledge are essential skills of a full-stack data scientist.
Basic Knowledge of Computer Science

Image Source: Dataintelliage
Data structures, algorithms, version control, and discrete mathematics are all essential topics in data science. Data science is essentially a computer science field, and the models you build and release will most probably be part of a more comprehensive solution. It’s vital to comprehend the significance of applying bubble sort versus merge sort to sort your input data. Furthermore, how you want to represent the data in the form of an object can impact how valuable the outputs are. Will you release the original data, or will you modify it? What information is vital to your model’s client? etc.
Mathematics

You should be proficient in linear algebra, calculus, probability, statistics, etc. when it math skills. These topics are necessary for a solid understanding of statistical analysis and machine learning, the two fundamental elements of data science.
Database Design
You must know how to create and interact with databases while collecting, cleaning, and processing data.
To arrange the data in use, you’ll need to be capable of writing queries in languages like SQL. Machine learning is majorly used in data analytics to create models that transform vast amounts of data and generate predictions based on that data.
Machine Learning
Machine learning is responsible for some of the most prominent data science algorithms, such as decision trees, k-means clustering, and support vector machines. The purpose of machine learning models is to forecast outcomes by finding patterns in data using algorithms. You become an efficient data scientist when you can predict future behavior. You can determine the outcomes of new input data by using training data and creating a model that can train from the supplied data and results. Machine learning entails highly complex mathematical processes that can analyze and interpret data without thousands of lines of complex code. Numpy, Pytorch, TensorFlow, Pandas, and other advanced tools and libraries are all part of this field.
Data Pipelines

Image Source: Alooma
As a full-stack data scientist, planning and executing regular deployments is a critical aspect of your role. You’ll need to build a pipeline so that users may input data and get accurate predictions. Pipelines automate the entire model deployment process making your model considerably more efficient.
Model Deployment
You must be able to deploy newer versions of your model once you’ve created your pipeline. You’ll need deployments to roll out any updates or fixes you apply to your model.
Industry Knowledge
Industry awareness is a fundamental skill that distinguishes a full-stack data scientist from a typical one. You must have a broad perspective of why you are generating these models. Organizations hire data scientists because they want to use data to make important business choices. You’ll need to have a solid grasp of the impact your model’s projections may have on the organization.
Characteristics of Full-Stack Data Scientists
Here are some one-liners that a full-stack data scientist delivers to a company and is accountable for in a company.
- They cater to a massive business impact because large projects entirely depend on their skills & craftsman.
- They are responsible for generating and extracting a high influx of data that will later help model training.
- They cater to cutting-edge development skills in various domains (web, AI, API, etc.)
- Companies can adopt the complete AI lifecycle & leverage their skills towards data-driven product automation.
- They have very high job satisfaction.
- Since they render the tasks of multiple profiles with lots of responsibilities, the full-stack data scientist is one of the highest-paid profiles in the industry.
But the benefit of such a profile comes with some imperfections and challenges.
Challenges and Imperfections
Due to some imperfections and challenges, many people consider this profile a hoax or myth. Yes, thinking from these perspectives is logical. These are:
- The full-stack data scientist’s profile is a multitude of different skills. So, who should interview these candidates to assess these dimensions and their connectivity?
- How much business knowledge, software development skills, and production deployment proficiency do companies expect from a full-stack data scientist?
- Where do they fit in the company?
- Are they jack of all trades and masters of none?
But, with time, the full-stack data scientists will overcome these challenges as well.
How can businesses benefit from hiring a full-stack Data Science?
The trend toward full-stack data scientists is booming, and companies are looking forward to leveraging such potential employees. Companies like Amazon and Google have started hiring or promoting data scientists and product managers to full-stack data scientists’ roles. Companies can depend mainly on these full-stack data scientists to build a full-scale application lifecycle and reap profits through AI and data-driven automation.
A company can create full-stack data science teams with a lifecycle view. The full-stack data scientists can manage projects and work as project managers. Full-stack data scientists are also responsible for developing AutoML systems & REST-based model development. That makes it easier for the company to deliver robust AI products. Because of full-stack data scientists, the time to market a product will reduce to a significant level.
Businesses are leaping to a new horizon where AI, ML, and data-driven products will lead the market. So, companies will require the potential of full-stack software developers and data scientists together into one superhero. Therefore, full-stack data scientists will be the new normal in the years to come.